SpaceLib
FineReaderToTxt
FineReaderToTxt (FRtoTxt) призвана помочь FineOCR.exe, запущенному из командной строки, сохранять результаты распознавания в файл без манипуляций с буфером обмена.
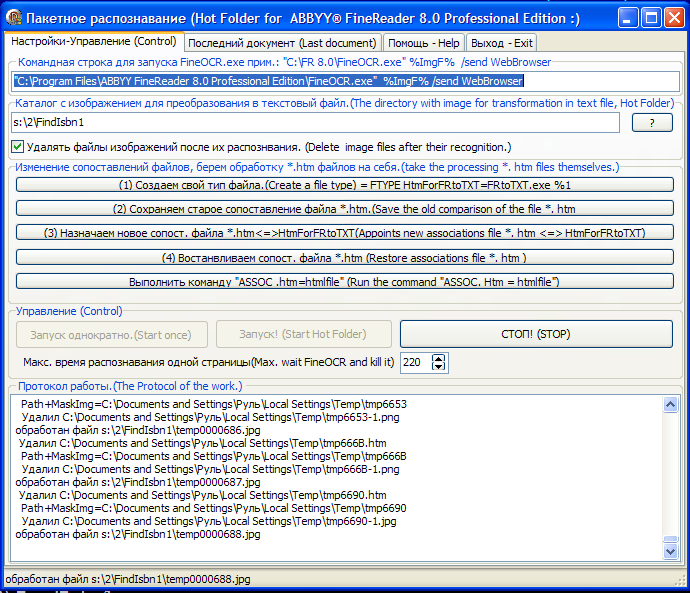
Как работает программа? FineReaderToTxt анализирует содержание «Каталога с изображением для преобразования в текстовый файл.(The directory with image for transformation in text file, Hot Folder)» и если там появляется графический файл, то запускает FineOCR.exe для его распознавания, т.е. превращения в плоский текст. Результат помещается туда же с именем файла аналогичным файлу с изображением, но с расширением txt. Все! Поддерживаются следующие форматы графических файлов: -jpg, tif, png, bmp.
Для корректной работы вам надо правильно указать путь к FineOCR.exe и выполнить несколько этапов настройки для перехвата обработки htm файлов FineReaderToTxt-ом. Нажимайте последовательно кнопки (1), (2), (3). Для FineReader-ра, FineReaderToTxt станет браузером которому он передаст результат распознавания. После завершения работы с FineReaderToTxt жмите кнопку (4), для восстановления ассоциации. Все эти манипуляции делаются обычными ДОСовскими командами! Для удобства заведите еще одного пользователя в системе и уже в его сеансе запускайте распознавание, т.к. FineOCR постоянно выкидывает окно процесса распознавания на передний план.
Подробнее.
По сути FineReaderToTxt частично реализует пакетное распознавание аналогичное ABBYY Hot Folder & Scheduling для версий Corporate Edition. FineReaderToTxt в своей работе использует FineOCR.exe, но передача результатов распознавания идет не через буфер обмена, а записывается сразу в файл на диске. ABBYY пожадничала и не стала явно включать такую возможность в FineOCR.exe, но мы ей помогли :). Отмечу, что FineOCR.exe сам умеет записывать результат работы в файл, но чтобы этим воспользоваться для полной автоматизации процесса распознавания, нужно "немного танцев с бубном", что и делает моя программа (всего несколько экранов кода :). Лично меня, как результат интересует только плоский текст (*.txt), htm-ки с рисунками "прибиваю" за не надобностью, но формат сохранения результата распознавания в принципе может быть любой из (MSWord, MSExcel, WordPro, WordPerfect, StarWriter, MSMail, txt, htm, pdf, PowerPoint). При некоторой доработке, на одной машине может работать несколько потоков распознавания одновременно, максимально загружая ваш многоядерный процессор, но в этом случае каждая копия FineOCR.exe должна быть запущена FineReaderToTxt-ом от имени разных пользователей. Надо всего лишь анализировать имя ВРЕМЕННОЙ паки, куда ABBYY FineReader помещает результаты распознавания. Например, если запустить ABBYY FineReader от имени пользователя FR01 то результат распознавания появится в паке:
C:\Documents and Settings\FR01\Local
Settings\Temp.
Сейчас FineOCR.exe после распознавания создает файл *.htm и передает его ОС, которая и пытается его открыть. Запускается копия FineReaderToTxt, которая понимает, что ее запустили с целью отобразить *.htm, вместо этого она записывает имя этого *.htm в файл Flag.txt и прекращает свою работу. Другая копия по таймеру опрашивает каталог, в котором должен появиться Flag.txt и когда это происходит, читает его и узнает полное имя *.htm файла с результатом распознавания. Далее при помощи Internet Explorer файл конвертируется в плоский текст. Если сразу создавать несколько процессов распознавания, значит их результаты надо записывать не в один Flag.txt, а в множество Flag01.txt, Flag02.txt и т.д.
Далее при анализе содержимого таких файлов, по пути C:\Documents and Settings\FR01\Local Settings\Temp смотреть от имени кого бы запущен конкретный FineOCR.exe и связывать результат с исходным файлом изображения. Понятно, что от имени одного пользователя одновременно можно запустить только один процесс распознавания, т.к. имена FineOCR.exe для *.htm назначает случайным образом. Я не стал пока реализовывать эту возможность, кто хочет, исходные тексты программы прилагаются!
23.06.09 Добавил новую опцию: сохранять htm файлы с результатами распознавания в отдельную папку. В этой папке, будут создаваться новые папки с именами распознанных графических файлов. Предполагается маленькая доработка FindISBN, которая будет создавать файлы изображений страниц по маске "Хэш-книги_номер-страницы". Тогда, всю библиотеку можно прогнать через FindISBN, задав заведомо большее количество страниц для обработки в одной книге. В результате получим материал для прямого размещения на сайте и его индексации. Некоторые книги, могут получиться вполне читаемыми, но большинство конечно будут выглядеть ужасно.
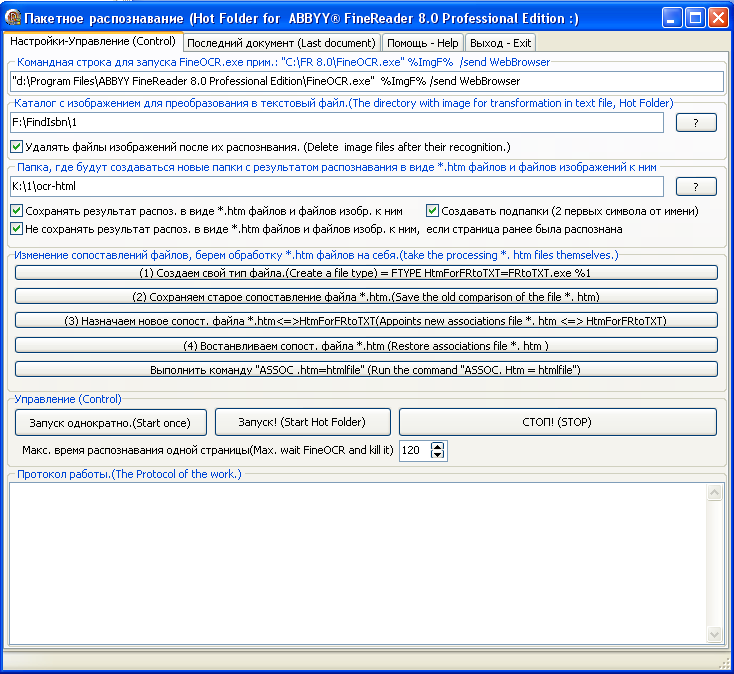
Для тех, кто хочет копать дальше, скажу, что можно получить не только распознанный текст в одном из форматов (MSWord, MSExcel, WordPro, WordPerfect, StarWriter, MSMail, txt, htm, pdf, PowerPoint), но сам пакет с результатами распознавания. Для этого надо модифицировать таблицу импорта функций FineReader-а, что бы перехватывать вызовы FineReader на удаления файлов пакета. Альтернативный метод описал Melirius в статье «Распознавание в FineReader 8 без вызова его GUI».
07.08.09 Добавил новый компонент....MultiFRtoTXT
Если вам необходимо на одном ПК запуск сразу несколько одновременно
работающих FindISBN и (FineReaderToTxt + ABBYY FineReader 8.0
Professional Edition[FineOCR.exe]), то сначала создайте несколько новых
пользователей в ОС, ровно столько сколько планируете запускать
копий FindISBN и (FineReaderToTxt), Например: FR01 и FR02.
Далее создайте в файловой системе несколько копий FindISBN
и (FineReaderToTxt) разместив их в папки с осмысленными именами, это
поможет вам не запутаться. Пример:
F:\FindIsbn\FindIsbn_1
F:\FindIsbn\FindIsbn_2
Регистрируйтесь
по очереди как пользователь FR01 и FR02, запуская в каждом свою копию
FineReaderToTxt из соответствующей папки (\FindIsbn_1\ineReaderToTx и \FindIsbn_2\ineReaderToTx). В том пользователе, где обычно работаете необходимо запустить MultiFRtoTXT.exe.
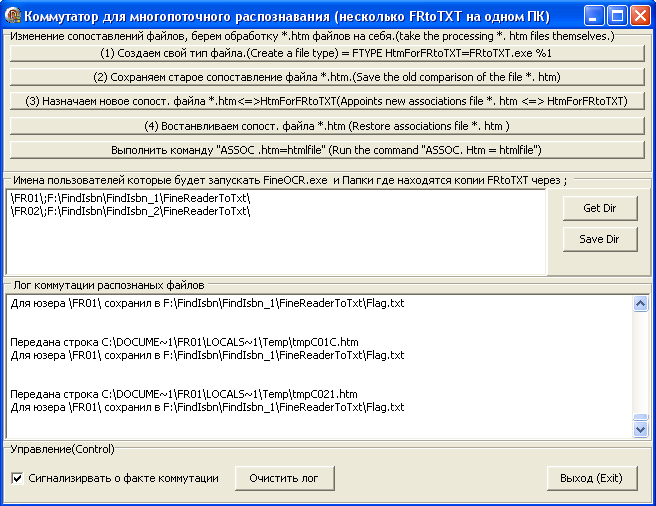
Это коммутатор, его надо правильно настроить. Как я уже отмечал,
проблема состоит в том, что FineOCR.exe всегда передает управление
после распознавания только одной программе, которая зарегистрирована в
операционной системе для просмотра указанного при запуске процесса
распознавания расширения. В нашем случае это программа, которая должна
отобразить htm файл. С помощью простейших ДОСовских команд мы возьмем просмотр таких файлов на себя (нажимая кнопки 1,2,3)
и далее анализируя полный путь к распознанному файлу узнаем, какая из
копий FRtoTXT запустила FineOCR.exe, именной этой копии и сообщим, что
файл распознан, и пора его обработать. Вот пример переданной строки от
FineOCR.exe к коммутатору:
C:\DOCUME~1\FR01\LOCALS~1\Temp\tmpBD9E.htm
Понятно,
что это результат распознавания, для копии FineReaderToTxt запущенной
от имени пользователя "FR01". Значит, её наш коммутатор должен
его сохранить в файле Flag.txt в папке, откуда была запущена именно эта
копия FineReaderToTxt. В нашем случае это будет файл:
F:\FindIsbn\FindIsbn_1\FineReaderToTxt\Flag.txt
, а в логе появится запись:
Передана строка C:\DOCUME~1\FR01\LOCALS~1\Temp\tmpBD9E.htm
Для юзера \FR01\ сохранил в F:\FindIsbn\FindIsbn_1\FineReaderToTxt\Flag.txt
В
текстовом многострочном поле "Имена пользователей которые будет
запускать FineOCR.exe и Папки где находятся копии FRtoTXT через
;" надо указать все варианты коммутации, причем имена пользователей
лучше брать в "\", пример:
\FR01\;F:\FindIsbn\FindIsbn_1\FineReaderToTxt\
\FR02\;F:\FindIsbn\FindIsbn_2\FineReaderToTxt\
Важно,
чтобы имена пользователей были короткими, т.к. иначе они будут
сокращены, как например было сокращено имя папки "\Documents and
Settings\" до "\DOCUME~1\". Желательно, чтобы используемые пользователи
были администраторами. При запуске и настройки копий FineReaderToTxt
кнопки 1,2,3 нажимать не надо!