Последние новости.
Здесь вы можете
прочитать о выходе обновлений к Базе
идентификации и о новых возможностях, которые я буду вносить
в свои программки. Тут-же будут публиковаться ссылки на новые
материалы, которые появятся на сайте.
Если вы решитесь
поделиться со всеми нами вашей уникальной частью Базы идентификации, то
выгружайте ее в файл, пакуйте rar-ом
(с опцией -m5) или зипом и шлите мне на
адрес SpaceLib
(собака) .narod.ru . Очень важно соблюдать
некоторые правила. О них читайте здесь.
28.04.15 "Обновил"
Exo -
двуязычный синтезатор речи с открытым исходным кодом. Обновления кода сделаны для команды, которая занимается "аудиовизуализацией"
08.10.13 "Обновил"
Exo -
двуязычный синтезатор речи с открытым исходным кодом. В мае 2013г. появился новый и очень качественный голос "Татьяна", подробнее здесьи здесь
. Да, немного есть польского акцента, но субъективно лучше "Катерины".
Если нет денег на легальную покупку, рекомендую "Татьяну" "лечить"
руками. karl_karlsson предлагает прямые ссылки на множество голосов, голоса "British English" у www.ivona.com
тоже хороши. Наконец для синтезаторов речи появились голоса,
которые обеспечивают достойный синтез двуязычной речи. Синтез, который
легко спутать на коротком отрывке текста с голосом живого диктора (пример). Что-то лучше похоже есть у ООО «Центр речевых технологий»,
которое освоило 152 млн рублей бюджетных денег, однако до настоящего
времени не выпустило на потребительский рынок этот продукт (пример) В Эхо добавил 3 строчки кода, которые позволяют запоминать ранее выбранные голоса.
06.06.12 Обновился
индекс сервера поиска магнет-ссылок
http://spacelib.dlinkddns.com/, на сегодня
проиндексировано 835
749 106
имен файлов, у более чем 40000 юзеров Direct Connect сетей. Появилось
немного свободного времени :). Теперь с http://spacelib.dlinkddns.com/,
можно через http ссылки вида http://spacelib.dlinkddns.com//cgi-bin/TestCGI?Download_tth=JDS7OMWBHPSHYS2VBVEUZ6XU3Q4OLBAOH4RVN6Q
скачивать файлы, как и у лучшей
в рунете библиотеки http://gen.lib.rus.ec/
.
Скачивать файлы можно только те, которые есть в моей шаре, а это более 450 000 файлов
формата pdf и djvu, объемом около 5Тбайт.
У http://gen.lib.rus.ec/
вы можете найти свыше 800 000
книг и журналов, правда в отличие от меня Либген коллекционирует англо
и русскоязычную литературу, я же стараюсь ограничивать себя только
русскоязычной (исключительно из-за ограничений по объему
хранения).
Возможность прямой закачки сделал потому, что теперь
благодаря
развитию широкополосного интернта в России (спасибо Путину за
web-камеры на выборах:) "средний" тариф за 550 руб. в мес предполагает
скорость отдачи файлов в 40
Мбит/с
и мой пиринговый клиент перестал занимать всю полосу пропускания
исходящего канала. С входящим каналом все еще лучше, ночью около 95Мбит/сек,
днем около 40 Мбит/с. Скоро отпуск, в котором хочу наконец
"собраться", и привести к воспроизводимому виду технологию создания
сервера поиска магент-ссылок, аналогичного http://spacelib.dlinkddns.com/ ,
выложив все программы с исходниками и описанием здесь, и на
RuLib.narod.ru.
06.09.10 Обновился
индекс сервера поиска магнет-ссылок
http://spacelib.dlinkddns.com/, на сегодня
проиндексировано 350
938 164
имен файлов, у более чем 29000 юзеров Direct Connect сетей.
24.07.10 Временно до 16.08.10 будут
не доступны сервисы на http://spacelib.dlinkddns.com/
к сожалению, они работают дома, а значит иногда отдолжны отдыхать
вместе с хозяином.
12.05.10 Обновил LibGenHash - теперь
хэш SHA1 считается в base32 (32 символа), а ранее считал в
base16 (40 символов)
25.03.10 Обновлена программа ED2K_FindDocs
, добавлена возможность создавать хардлинки на файлы, найденные по
хешу. Теперь не обязательно менять названия и месторасположение файлов,
для получения "благозвучных" имен.
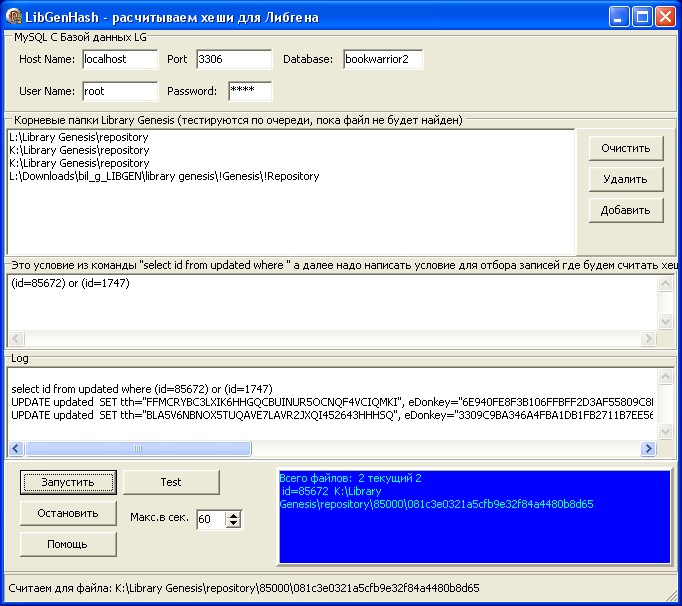
11.02.10 Выложена
программа LibGenHash
-программа рассчитывает хэши для БД
ЛибГена (рис).
27.01.10 Обновлена программа ED2K_FindDocs , добавлена новая статья "Присваиваем "человеческие имена"
файлам-книгам из библиотеки Library Genesis." В программе
поддерживаются самые распространенные типы хэшей. Это значит, что для "рыбаков"
она открывает новые колосальные возможности. Так например, используя
файл-листы пользователей скаченные из хабов пиринговой сети Direct
Connect и программу
SSearch.exe можно извлекать
данные для идентификации миллионов файлов. Для этого в
SSearch.exe сделайте поиск и
результаты сохраните в файлах *.finds, а в ED2K_FindDocs можно
использовать их для создания БД идентификации.
03.11.09 Обновлена База идентификации.
В ней описано 119609
документов.
22.08.09 Обновлена База идентификации.
В ней описано 96767
документа.
07.08.09
Добавил к FineReaderToTxt (Подробнее..)
новую программу "Коммутатор
для многопоточного распознавания (несколько FRtoTXT на одном ПК)", т.е.
теперь на одном ПК может работать сразу несколько связок FindISBN
и (FineReaderToTxt + ABBYY FineReader 8.0 Professional
Edition[FineOCR.exe]) максимально загружая ваш многоядерный процессор.
23.06.09
Добавил в FineReaderToTxt (Подробнее..)
новую опцию:
сохранять htm файлы с результатами распознавания в отдельную папку. В
этой папке, будут создаваться новые папки с именами распознанных
графических файлов. Предполагается маленькая доработка FindISBN,
которая будет создавать файлы изображений страниц по маске
"Хэш-книги_номер-страницы". Тогда, всю библиотеку можно прогнать через
FindISBN, задав заведомо большее количество страниц для обработки в
одной книге. В результате получим материал для прямого размещения на
сайте и его индексации. Некоторые книги, могут получиться вполне
читаемыми, но большинство конечно будут выглядеть ужасно.
19.06.09 В ходе работы над
записями РГБ (http://torrents.ru/forum/viewtopic.php?t=1470611)
и БД магазина Озон (http://www.ozon.ru/multimedia/yml/partner/div_bs.zip),
родился файл "baza.txt" (http://narod.ru/disk/10050885000/baza.rar.html)
для FindISBN и AllDocView
в котором содержится 1358499 записей о книгах. Все записи имеют ISBN.
Напомню что это маленькая текстовая БД которая играет своего рода
функцию КЭШа, позволяя уменьшить количество обращений к онлайновым
каталогам. Размер baza.rar 43,515,795 байт.
09.06.09 Обновлена База идентификации.
В ней описано 83343
документа. Пополняю за счет отличной библиотеки http://gen.lib.rus.ec/
28.05.09 Выложил http://narod.ru/disk/9247383000/db-rsl.rar.html
это
библиографическая база книг РГБ в формате в CSV (только след. поля:
245$a, 245$b, 245$c, 260$c, 300$a, 020$a т.е.Автор(ы), Название, год
издания, страниц, ISBN) . Всего 3026678 записи. База взята с торентс.ру
и конвертирована в CSV "руками" с использованием MarcEdit. Для
полноценного использования в FindISBN
требуется доп. обработка, над чем и
работаю.
31.03.09 Выложил новую версию
SSearch.exe.
В SSearch интегрирован Sphinx.
Это маленькая революция, большая будет с встройкой в SSearch Web
сервера для организации поиска в хабах "одним кликом мыши". То что
будет, можно протестировать здесь: http://spacelib.dlinkddns.com/.
04.03.09 В процессе работы над
совершенствованием SSearch
принято решение об интеграции в него поисковой системы Sphinx. Все будет
работать без СУБД.
Уникальные
возможности Sphinx-а
позволят обойтись своим «самопальным», простейшим
индексным файлом (это не
относится к индексам Sphinx-а).
SSearch и раньше мог «медленно» искать по практически неограниченному
количеству расшаренных файлов, а теперь он будет искать очень быстро и
с учетом
морфологии русского языка. Тестовое количество расшаренных файлов
175 000 000, время поиска около 1 сек. Установлено,
что
Yandex.Server-3.8.3 Free Edition не масштабируемое решение для поиска!
Все бесплатные проприетарные поисковики проигрывают по масштабируемости
открытым и бесплатным!
02.02.09 Выложил новую версию
SSearch.exe
, главное: оптимизированы алгоритмы создания
html файлов в режиме Турбо-поиск (
теперь
на создание 300000 файлов уходит 6-10 мин., против 60 мин для старого
кода). Все для сервиса http://spacelib.dlinkddns.com/:17000
, который позволяет мгновенно
искать в отиндексированных хабах, получать информацию об активных магнетах
см. http://spacelib.dlinkddns.com/:17000/yar
(там есть признак активности - пользователь с нужным магнетом
в хабе? [квадрат: красный - нет, зеленый - да]).
И еще много чего. Победил Yandex.Server-3.8.3 Free Edition, теперь он
умеет создавать большие
индексы.
Метод назвал "Инъекция папок" :) . В
документации на него написано "Не содержит лицензионных ограничений на
число индексируемых документов, их размер или суммарный размер индекса
" - наглая ложь!
Пишу прогу для
автоматизации процесса.
02.02.09 Выложил FineReaderToTxt (Подробнее..)
В у нее есть не объяснимая для меня особенность, до обработки первого
документа в ней должна быть открыта закладка "Последний
документ"-"Html". Разбираться пока некогда.
09.01.09 Запущен сервер поиска
магнет ссылок http://spacelib.dlinkddns.com/:17000.
Сервер работает в тестовом режиме, пока это Яндекс (Yandex.Server-3.8.3
Free Edition) , однако у него есть
серьезные проблемы с безопасностью и масштабируемостью. По этому
ведутся работы по исследованию sphinx (Обсуждение).
10.11.08 Написана и активно
тестируется новая программа FineReaderToTxt
(скриншот прототипа здесь). Она реализует
пакетное распознавание (Hot Folder for ABBYY® FineReader 8.0
Professional Edition :). Её основная задача помочь FindISBN
надежнее искать ISBN и ISSN в электронных документах,
кроме того создавать качественные файлы аннотации в Txt формате для документов не
имеющих текстового слоя в полностью автоматическом режиме.
FineReaderToTxt в своей работе использует
FineOCR.exe, но передача результатов распознавания идет не
через буфер обмена, а записывается сразу в файл на
диске. ABBYY пожадничала и не стала явно включать
такую возможность в FineOCR.exe, но мы ей помогли :). Альтернативой FineReaderToTxt
является корпоративная редакция FineReader версии 9.0. Отмечу, что
FineOCR.exe сам умеет записывать результат работы в файл, но чтобы этим
воспользоваться для полной автоматизации процесса распознавания, нужно
"немного танцев с бубном" , что и делает моя программа (всего несколько
экранов кода :). Лично меня, как результат интересует только плоский
текст (*.txt), htm-ки с рисунками "прибиваю" за
не надобностью, но формат сохранения результата распознавания в
принципе может быть любой из (MSWord, MSExcel, WordPro, WordPerfect,
StarWriter, MSMail, txt, htm, pdf, PowerPoint). При некоторой
доработке, на одной машине может работать несколько FineOCR.exe одновременно,
максимально загружая ваш многоядерный процессор, но в этом случае
каждая копия FineOCR.exe должна быть
запущена от имени разных пользователей. Скоро выложу с исходниками.
Побудительным мотивом "временно" отказаться от пакетного
распознавания CuneiForm в пользу FineOCR стала моя новая программа
"Поиск авторского названия книги путем сравнения текстового слоя
документа с библиографическим каталогом" - FindAName.
Проще говоря, если в тексте есть название книги, оно с помощью FindAName
находится и записывается в файл сателит документа с расширением *.NameBook.
Теперь можно в автоматическом режиме находить
авторское название документа даже если в нем нет ISBN, но такое название существует
в библиографическом каталоге (скриншот прототипа здесь). К сожалению бесплатный CuneiForm при
создании текстового
слоя
существенного проигрывает FineReader в качестве распознавания, а для сравнения
тестовых фрагментов это очень важно. Качественный текстовый слой, так
же важен и для персональных поисковых систем, которые проиндексируют
вашу библиотеку и позволят быстро найти нужный документ. Для того, что бы правильно найти
название книги нужны большие и качественные библиографические каталоги,
коих у меня пока нет, кроме каталога Озона. Если знаете, где
взять что то лучшее, чем каталог Озона пишите мне на
адрес SpaceLib
(собака) .narod.ru . После всесторонней
доработки и тестирования
выложу с исходниками.
22.10.08
Обновлена База
идентификации. В ней описано 57634
документа. На сайте http://ewrika-ru.narod.ru/
были выложены книги практически не встречающиеся в сети
18.09.08 Обновлена База идентификации.
В ней описано 56853 документа. На сайте http://rulib.narod.ru/
была выложена тестовая версия FindISBN
(программа для полуавтоматического поиска названий книг)
04-08-08 В
SSearch.exe
добавлен Турбо-поиск - мгновенный поиск,
использующий любую доступную персональную поисковую систему.
01.08.08 Обновлена База идентификации.
В ней описано 54352
документов (лето однако). Открылся сайт http://rulib.narod.ru/ посвященный
пиринговым библиотекам.
01.07.08 Обновлена База идентификации.
В ней описано 54010 документов.
05.06.08 Обновлена База идентификации.
В ней описано 51903 документа.
09.05.08 В
SSearch.exe
- добавлен оптимизатор (объединяю списки файлов пользователей с
одинаковыми никами, но с разных хабов)
17.04.08 Выкладываю
SSearch.exe.
Это программа офф-лайн поиска файлов в p2p-сетях на основе StrongDC или
его клонов. Она снимает ограничения на сложность и анонимность поиска.
Программа также поможет организовать массовую загрузку "правильно
отобранных" документов из пиринговой сети для вашей библиотеки.
Прототипом данной программы была описанная ранее в новостях программа
LoadFromHab. Существенно дополнена SpaceLib . В
ней появился механизм универсальных закладок на документы,
иерархического классификатора документов библиотеки и "информационного
поля ваших интересов". FindISBN ждет своего
часа.
02.04.08 Обновлена База идентификации.
В ней описано 48504 документа. Пополнена за счет
библиотеки Колхоза. В программе FindISBN добавлен поиск названий книг в
Сигле (www.sigla.ru), что решило проблему поиска названий англоязычной
литературы. И существенно подняло процент найденных названий книг по ISBN.
22.03.08 Обновлена База идентификации.
В ней описано 36961 документ (объем более 200ГБайт). Скоро докачаю
библиотеку Колхоза (около 62 Гиг), преобразую его к приемлемому виду и
пополню Базу идентификации. Ожидаю существенную прибавку количества
записей. Написана новая программа - FindISBN.
Её задача находить ISBN в файлах pdf и
djvu. Найдя ISBN она сначала по базе
Озона ищет название книги. Если название(я) найдено(ы) сохраняет его(их) в
специальном файле (имя файла документа+.NameBook).
Если название не найдено обращается к каталогу Российской
государственной библиотеки (более 700000 записей) и ищет там. Как
показала практика по найденному названию автоматически давать имена
документам нельзя. Нужен ручной контроль, т.к. могут быть ошибки
распознавания ISBN или множество других ньюансов. По этому доработана
AllDocView. Она распознает, что у документа есть файл
сателит с расширением .NameBook
и автоматически предлагает использовать найденное ранее название
документа. FindISBN активно тестируется. Её надо дополнить
распознаванием ISSN для
журналов и поиском названий для англоязычной литературы. Для
распознавания текста и выделения из него ISBN,
используется бесплатный CuneiForm. Он конечно хуже чем
Фаинридер от ABBYY, но имеет важное преимущество - сохранение
результата распознавания в файл. Т.е. на одной машине с многоядерным ЦП
можно одновременно запускать несколько копий FindISBN и CuneiForm. Они
не будут мешать друг другу и будут максимально загружать процессор и
массив жестких дисков.
Написана и тестируется программа LoadFromHab. Её задача
поиск в пиринговых сетях (для клиентов StrongDC ) любых
файлов путем анализа листов загрузки. А так-же, массовой загрузки
документов, которых у вас нет. Т.е. вы задаете некоторые критерии для
поиска файлов в листах загрузки тысяч
пользователей, далее найденный список документов подвергаете контролю и
если вас все устраивает формируете список загрузки для StrongDC (файл
Queue.xml). У меня не анлим, но внутренний трафик бесплатен (исходящий
1Мбит входящий 8Мбит). Практика показала, что при некоторых условиях
можно добиться скоростей закачки 4-6Мбита, качая только книги и
журналы. Скорость, объем и "качество" поступающей литературы выше чем
при "рыбалке", т.к. при формировании списков загрузки вы можете
задавать "умные" критерии отбора документов. Как только количество
"багов" существенно уменьшится, все программы будут выложены на сайте
вместе с исходниками.
13.02.08 Обновлена База идентификации.
В ней описано более 30000 документов. Выложена тестовая версия AllDocView. В ней добавлен поиск
по ISBN, но только пока в
ручном режиме. Т.е. распознали ISBN,
щелкнули по кнопке ("лупа"), и если такой номер есть в базе Озона то
появится окно Новая книга с уже готовым названием книги. База названий
книг Озона выложена на странице
загрузки - состоит из двух файлов!
23.01.08 Обновлена База идентификации.
В ней описано более 27000 книг и журналов. Тестирую AllDocView, прикрутил к ней базу
ОЗОНА. Теперь распознав ISBN через
ABBYY Screenshot Reader, можно сразу будет искать название книги в
базе ОЗОНА (более 312000 записей).Сей метод уверенно работает
на новых книжках 2006-2008г. издания. Для справки: база книг Озона в
упакованном виде занимает около 6 Мбайт и скоро будет доступна у меня,
как и новая версия AllDocView.
В тех документах, где будет присутствовать текстовый слой, поиск
названия книги по ISBN будет
реализован в полуавтоматическом режиме и фоновом потоке.
11.01.2008 Обновлена База идентификации.
В ней описано более 20000 книг и журналов.
18.12.2007 Обновлена
База
идентификации. Тестирую механизм
"закладок" на любимые книги для SpaceLib, новую версию не
выложил, но уже скоро будет доступна. Тестирую "Черновую Базу
Идентификации", ориентировочно в ней будет информация о 50000-70000
уникальных документов формата pdf,
djvu, chm.
15.11.2007 выложил первую полную версию AllDocView.
10.11.2007 выложил новую программу
ED2K_FNDocs, она как и FindNameDocs предназначена для
идентификации файлов.
С ED2K_FNDocs идет база
идентификации книг и журналов из "Коллекции
технической литературы" МГУ на 16000 книг . Обновлена База идентификации.
10.10.2007 Обновлена База идентификации
и некоторые программы.(ProcessingArchive , SpaceLib
, RenToDir). Скоро выложу Sito2.
12.09.2007
Обновлена База
идентификации. Буду стараться обновлять
ее еженедельно. Продолжаю тестировать "долгострой"
AllDocView и MViewing.
Первая использует установленные в системе ActiveX
библиотеки для просмотра и сортировки документов,
вторая для просмотра, прослушивания и сортировки медиа файлов. AllDocView почти
готова, осталось написать только Help,
а с MViewing
придется повозиться.
12.08.2007
Выложен на тестирование агрегатор новостных лент
RSSSky
- умеет читать в слух новостные сообщения на русском и английском языке
("билингва":).
10.07.07 программа для чтения "пойманных"
новостных лент активно тестируется и называется RSSSky.
Кроме подбора "пойманных" новостных лент имеет возможность их
загрузки из сети, все сообщения хранит в своей базе, имеет расширенные
возможности поиска в ней. Скоро ее выложу.
13.06.07 идет
тестирование возможности загрузки и разбора новостных лент в формате XML
для
ЭХО. Пока не решил, оформить это в
виде отдельной программы или интегрировать в ЭХО.
03.06.07 выложена новая версия
программы синтеза речи ЭХО.
Добавлены возможности выбора скорости и типа битрейта при конвертации в
MP3. Теперь
пользователь сам выбирает, каким голосом читать числа.
14.05.2007
выложена моя статья SAPI XML TTS для разработчиков
прикладных программ.
14.05.2007
выложена новая версия программы синтеза ЭХО.
Исправлены некоторые ошибки, расширена поддержка обработки текста,
введена поддержка XML тэгов,
разрешил работу с rtf файлами.
{kind=link}